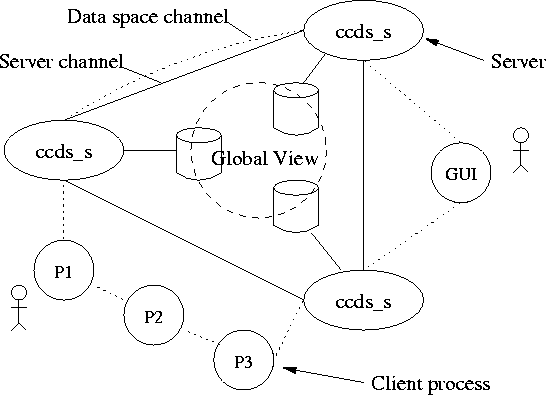
The CCDS architecture (fig. 1) is based on a set of distributed data servers known as ccds_s. Together, the data servers implement a global name space for objects in the data space. Each data server serves as a centralized server for the objects on that server; hence, concurrency control is simply achieved by serializing requests to a centralized server. A data server is instantiated on any machine where one or more clients is accessing the data space. Several reasons motivated us to chose this hybrid model; using a centralized scheme immediately implies a simple and robust concurrency model, as well as simplifying other operations, such as latecomer support. Furthermore, with distributed servers, locality of access can be exploited which means that data objects can be located nearest, in terms of communication cost, to where the object is accessed most often. The distributed servers can also serve as a framework for a future extension where data objects are fragmented across servers. However, for a tightly coupled synchronous access pattern where many clients access one object, a replicated architecture would be more appropriate.
From a clients perspective the physical location of an object is transparent and objects can migrate from one server to another in order to achieve better performance. A client library handles client communication with data servers and provides applications with a simple programming interface.
The data servers communicate on a well known server channel to maintain a consistent global naming space, data servers also join a well known data space channel. When a client joins the data space, it joins the data space channel. The underlying communication functionality for reliable and atomic communication semantics is handled by the Collaborative Communication Transport Layer (CCTL) [1]. The CCTL also provide whitepage services for naming and membership operations. To access an object initially, for example to open a data file, the client library broadcasts a request on the data space channel, every data server then responds with a positive or negative reply. From then on, all accesses to the object occur in point to point mode with the particular server that serves the object.
The objects on a particular data server are physically stored on a storage medium that is accessible from the data server via the operating system. Ideally, for best performance, the storage is local to the machine where the data server is running.
The current implementation of CCDS supports a file object type. Operations provided by the CCDS programming interface for the file object type include standard file operations known from operating systems, such as: open, close, read, write, segment lock, unlock, and seek. In addition to these operations, the API includes calls for joining and leaving the CCDS, for importing a file object from a local filesystem to CCDS, conversely, unimporting from CCDS to local filesystem, calls for listing of CCDS objects, as well as other management functions. CCDS also has functionality for migrating an object from a remote server to a local server. With a local server we refer to a server running on the same machine as the client. The advantage of migrating an object to a local server is lower latency and higher throughput resulting from less communication.
In addition to the familiar single process file object access semantics, CCDS facilitates collaborative access to CCDS file objects through several shared file offset pointers. A shared file pointer is a file pointer that is shared among several processes that have the file object opened, pointer update semantics guarantee that every process has the same view of the shared file pointer. Currently, one shared read pointer and one shared writer pointer per file are supported. In addition to shared pointers, a process can open a file object with a local file pointer that is accessible only to that particular process.
Clients can request asynchronous notifications of data space content changes from the CCDS data servers. Notification events are passed to a client via a callback function implemented by the client. Currently, notification events are generated when a new object is created in the data space, or when a object is removed from the data space. We use the notification events to implement a graphical user interface client for the CCDS that displays the data space content, and which also has functions for importing, unimporting, and viewing objects.